Ship Faster with Trunk-Based Development and Feature Flags
Fast delivery is not just about writing code quickly; it is about reducing risk while increasing learning speed. Two practices consistently enable this balance in modern teams: trunk-based development (TBD) and feature flags. Together, they shorten feedback loops, minimize merge conflicts, and allow releases to be decoupled from deployments.
This article walks through how to adopt TBD and feature flags pragmatically, what to measure, and how to avoid common failure modes. The goal is simple: ship small, ship often, and stay in control.
Why trunk-based development changes the pace of delivery
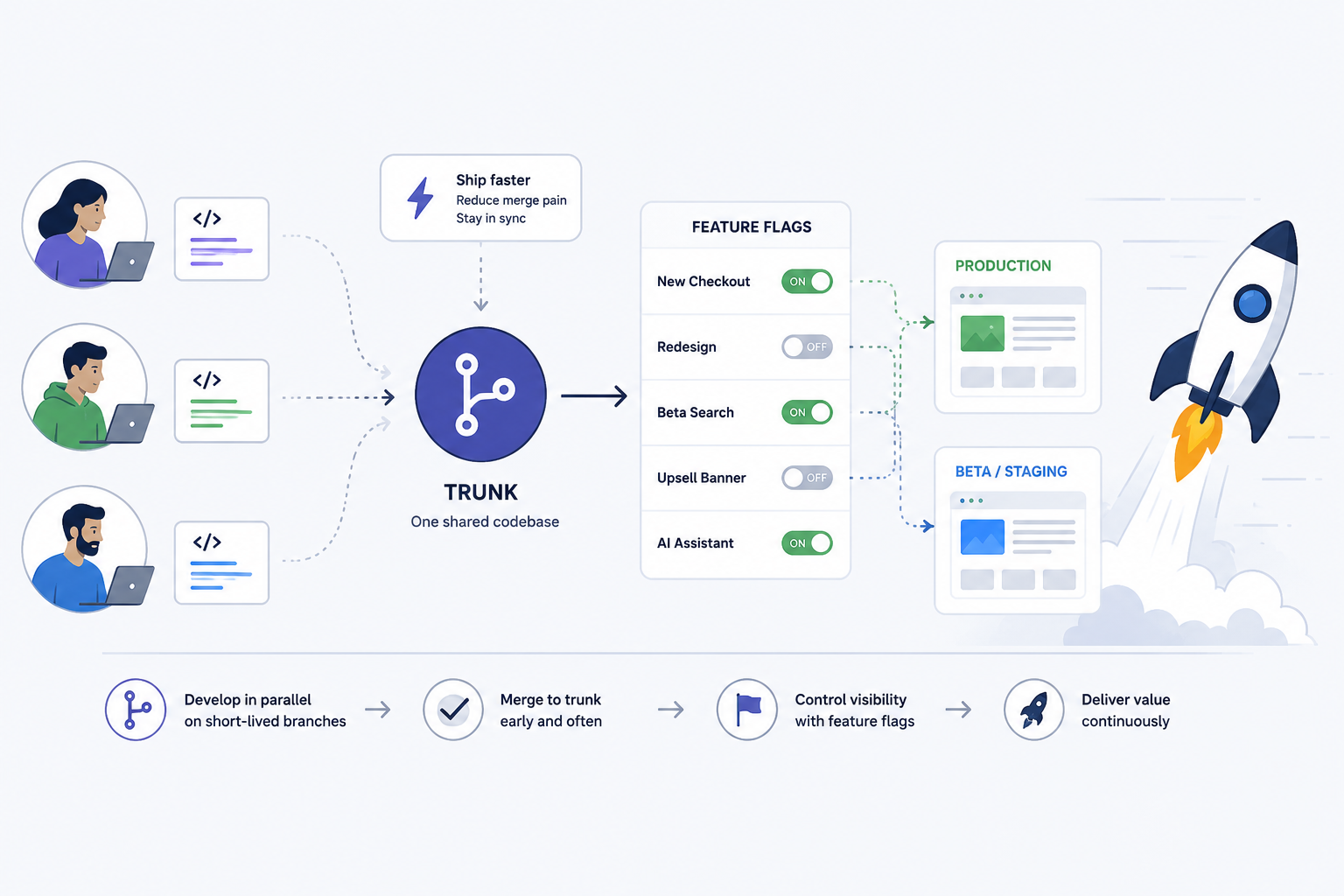
Trunk-based development centers work on a single shared branch (often main) with very short-lived branches when needed. Instead of weeks of divergence and painful integration, teams integrate continuously, keeping the codebase in a releasable state.
The biggest advantage is not ideological purity; it is operational. Short-lived changes reduce the probability of conflicting edits, lower the cognitive load of reviewing, and make debugging easier because each merge introduces a small, traceable set of modifications.
- Less merge debt: merging daily (or multiple times per day) prevents large, risky integration events.
- Faster feedback: CI runs on small changes complete sooner and are easier to fix.
- Cleaner releases: when main is always releasable, release planning becomes a product decision, not an engineering scramble.
Feature flags: decouple deployment from release
Feature flags let you deploy code to production without immediately exposing functionality to users. This creates a safety buffer: you can ship frequently, but release intentionally. The decoupling is the unlock that makes TBD comfortable even for teams in regulated or high-availability environments.
In practice, the combination looks like this: engineers merge incomplete work behind a flag, CI validates main, and deployments can happen continuously. Product and engineering then choose when to enable the feature for internal users, a beta cohort, or everyone.
A practical operating model (with examples)
Adopting TBD and flags is easier when you define a simple operating model that everyone follows. Start with a lightweight rule: every change merged into main must be either production-ready or safely hidden behind a flag.
Example: you are refactoring a checkout flow that will take two weeks. Instead of a long-lived branch, merge incremental slices daily: new API contracts, parallel code paths, and UI components, all gated. Production always contains the new path, but it is disabled for users until the end-to-end behavior is complete.
- Create a flag per user-visible capability: name it by intent (for example, checkout_v2_enabled) rather than implementation details.
- Use progressive delivery: enable for internal accounts, then 1%, then 10%, then 50%, then 100%.
- Keep diffs small: prefer many small merges over one large merge; target changes that can be reviewed in minutes, not hours.
- Pair flags with metrics: define success and rollback signals before enabling the flag broadly.
Quality gates that keep main releasable
TBD only works when the team treats the main branch as sacred: it must stay green. That means setting up quality gates that run quickly, provide clear signals, and fail deterministically. If builds are flaky or slow, developers will hesitate to merge, and the workflow will collapse back into long-lived branches.
Focus your pipeline on layered confidence. Run fast checks on every commit, then deeper validation after merge. A strong pattern is: pre-merge unit tests and static analysis, post-merge integration tests, and periodic end-to-end tests. This balances speed with coverage.
- Pre-merge: linting, type checks, unit tests, security scanning for dependencies.
- Post-merge: integration tests against real services or containers, contract tests for APIs.
- Nightly or scheduled: end-to-end suites, performance smoke tests, chaos experiments where appropriate.
Actionable tip: define an explicit policy for broken builds (for example, fix-forward within one hour, or revert). The policy matters more than the tooling, because it aligns behavior under pressure.
Flag hygiene: avoiding the “flag graveyard”
The most common feature-flag failure is accumulation: flags that never get removed, turning the codebase into a maze of conditions. This increases cognitive load, introduces subtle bugs, and makes testing harder because the number of states explodes.
Prevent this with lifecycle management. Treat every flag as a temporary artifact with an owner, an expiration expectation, and a removal plan. For long-lived flags (for example, pricing experiments), isolate them cleanly and document expected states.
- Set owners: every flag should map to a team and a tracking ticket.
- Use expiry reminders: add automated alerts when a flag is older than a threshold (for example, 30 or 60 days).
- Delete aggressively: once fully rolled out or abandoned, remove the flag and dead code in the next sprint.
- Test critical combinations: for high-risk areas, explicitly test “flag on” and “flag off” paths in CI.
Observability and safe rollouts: measure, then expand
Feature flags are only as safe as your ability to detect issues quickly. Before enabling a new capability broadly, define what “healthy” means: latency, error rate, conversion rate, and key workflow completion. Instrument those metrics and set alerts so you can react in minutes, not hours.
A practical rollout checklist is: deploy behind a flag, enable for internal users, monitor for a fixed window, ramp to a small cohort, compare metrics to baseline, then expand gradually. If regressions appear, disable the flag immediately and investigate without rushing a hotfix.
Actionable tip: use correlation IDs and structured logs so you can compare requests that went through the new path versus the old path. This makes root-cause analysis dramatically faster during partial rollouts.
Getting started: a 2-week adoption plan
If your team currently uses long-lived branches and infrequent releases, you can still adopt this approach without a big-bang process change. Start small, prove the value, then expand.
- Week 1: pick one service or repository, enforce “main must be green,” and reduce branch lifetime to under 24 hours.
- Week 1: introduce a basic flag mechanism (even a simple config-backed boolean) and ship one small feature behind a flag.
- Week 2: add progressive rollout steps (internal, 1%, 10%, 100%) and define metrics and rollback triggers.
- Week 2: add flag ownership and a removal rule so hygiene is maintained from day one.
The payoff is cumulative: fewer merge emergencies, faster releases, and a codebase that stays deployable. Over time, the team spends less effort coordinating and more effort delivering.


0 Comments
1 of 1